Dieser Artikel entstand im Rahmen desData-Science-Blog
Einführung
Wann immer wir ein maschinelles Lernmodell erstellen, speisen wir Anfangsdaten ein, um das Modell zu trainieren. Und dann geben wir einige unbekannte Daten (Testdaten) ein, um die Leistung des Modells zu verstehen und auf unsichtbare Daten zu verallgemeinern. Wenn das Modell mit unsichtbaren Daten gut funktioniert, ist es konsistent und kann eine breite Palette von Eingabedaten mit hoher Genauigkeit vorhersagen; Dieses Modell ist also stabil.
Aber das ist nicht immer der Fall!! Modelle für maschinelles Lernen sind nicht immer stabil, und wir müssen die Stabilität von Modellen für maschinelles Lernen bewerten. Hier kommt die Kreuzvalidierung ins Spiel.
„Einfach ausgedrückt ist die Kreuzvalidierung eine Technik, mit der die Leistung unserer maschinellen Lernmodelle anhand unsichtbarer Daten getestet wird.“
Laut Wikipedia ist Kreuzvalidierung der Prozess der Bewertung, wie sich die Ergebnisse einer statistischen Analyse zu einem unabhängigen Datensatz verallgemeinern lassen.
Es gibt viele Möglichkeiten zur Kreuzvalidierung und wir werden in diesem Artikel mehr über 4 Methoden erfahren.
Lassen Sie uns zunächst die Notwendigkeit einer Kreuzvalidierung verstehen!
Warum brauchen wir eine Kreuzvalidierung?

Angenommen, Sie erstellen ein maschinelles Lernmodell, um ein Problem zu lösen, und Sie haben das Modell mit einem bestimmten Datensatz trainiert. Wenn Sie die Modellgenauigkeit anhand der Trainingsdaten überprüfen, liegt sie näher bei 95 %. Bedeutet dies, dass Ihr Modell sehr gut trainiert wurde und aufgrund der hohen Genauigkeit das beste Modell ist?
Nein, ist es nicht! Da Ihr Modell mit den gegebenen Daten trainiert wird, kennt es die Daten gut, erfasst selbst die kleinsten Variationen (Rauschen) und verallgemeinert die gegebenen Daten sehr gut. Wenn Sie das Modell völlig neuen, unsichtbaren Daten aussetzen, kann es möglicherweise keine genauen Vorhersagen treffen und nicht auf neue Daten verallgemeinern. Dieses Problem wird als Überanpassung bezeichnet.
Manchmal trainiert das Modell auf dem Trainingssatz nicht gut, weil es keine Muster finden kann. Dann würde es auf dem Prüfstand auch nicht gut funktionieren. Dieses Problem ist als falsche Passform bekannt.
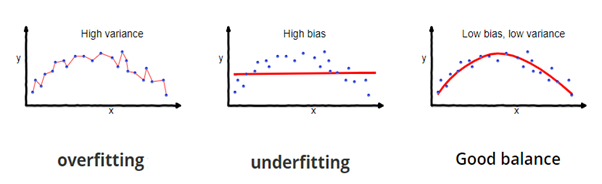
Bildquelle: fireblazeaischool.in
Um Overfitting-Probleme zu überwinden, verwenden wir eine Technik namens Kreuzvalidierung.
KreuzvalidierungEs ist eine Resampling-Technik mit der Grundidee, den Datensatz in 2 Teile zu teilen: Trainingsdaten und Testdaten. Trainingsdaten werden verwendet, um das Modell zu trainieren, und unsichtbare Testdaten werden für die Vorhersage verwendet. Wenn das Modell mit den Testdaten gut funktioniert und eine gute Genauigkeit aufweist, hat das Modell die Trainingsdaten nicht überangepasst und kann für die Vorhersage verwendet werden.
Lassen Sie uns eintauchen und einige der Modellbewertungstechniken lernen.
1. Wärmemethode
Dies ist die einfachste Bewertungsmethode und wird häufig in Machine-Learning-Projekten verwendet. Hier wird der gesamte Datensatz (Population) in 2 Sätze aufgeteilt: Trainingssatz und Testsatz. Die Daten können je nach Anwendung in 70-30 Ö 60-40, 75-25 Ö 80-20 oder 50-50 aufgeteilt werden. Generell sollte der Anteil der Trainingsdaten größer sein als der der Testdaten.
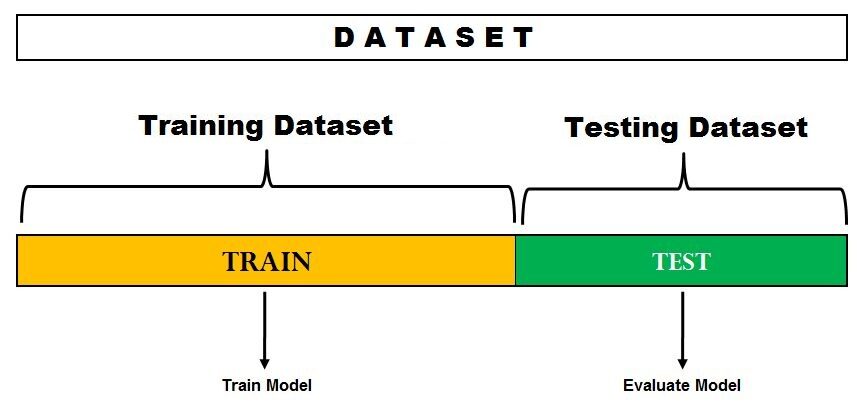
Bildquelle: DataVedas
Die Datenaufteilung ist zufällig und wir können nicht sicher sein, welche Daten während der Aufteilung im Bootcamp landen, es sei denn, wir geben random_state an. Dies kann zu einer extrem hohen Varianz führen, und jedes Mal, wenn sich die Teilung ändert, ändert sich auch die Genauigkeit.
Diese Methode hat einige Nachteile:
- Bei der Wait-Methode sind die Testfehlerraten sehr variabel (hohe Varianz) und hängt ganz davon ab, welche Beobachtungen in der Trainingsmenge und der Testmenge landen.
- Nur ein Teil der Daten wird zum Trainieren des Modells verwendet (hohe Vorspannung), was bei kleinen Datenmengen keine gute Idee ist und zu einer Überschätzung des Testfehlers führt.
Einer der Hauptvorteile dieser Methode besteht darin, dass sie im Vergleich zu anderen Kreuzvalidierungstechniken kostengünstig ist.
Schnelle Implementierung der Hold Out-Methode in Python
aus sklearn.model_selection import train_test_split
X = [10,20,30,40,50,60,70,80,90,100]
Bahn, prueba = train_test_split (x, test_size = 0,3, random_state = 1)
imprimir(“Bahn:”, X_Zug, “Comprovar:”, X_test)
Produktion
Tipp: [50, 10, 40, 20, 80, 90, 60] Prüfen: [30, 100, 70]
Hier,random_statees ist der Samen der Reproduzierbarkeit.
2. Überspringen Sie eine der Kreuzvalidierungen
Bei dieser Methode teilen wir die Daten in Test- und Trainingsdatensätze auf, jedoch mit einem Unterschied. Anstatt die Daten in 2 Teilmengen aufzuteilen, wählen wir eine einzelne Beobachtung als Testdaten aus und alles andere wird als Trainingsdaten markiert und das Modell wird trainiert. Nun wird die zweite Beobachtung als Testdaten ausgewählt und das Modell mit den restlichen Daten trainiert.
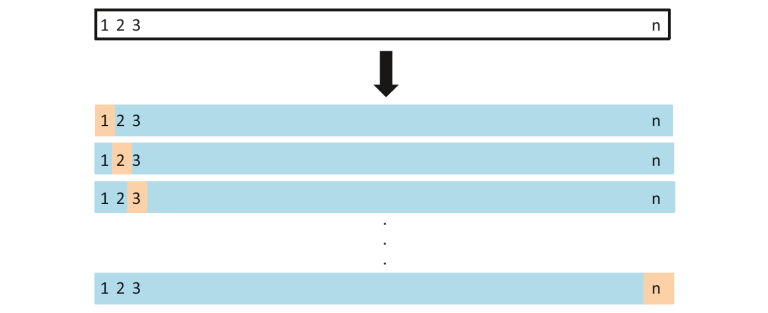
Bildquelle: ISLR
Dieser Prozess wird ‘n’ fortgesetzt und der Durchschnitt all dieser Iterationen wird berechnet und als Testsatzfehler geschätzt.
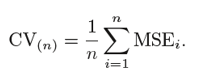
Wenn es um Testfehlerschätzungen geht, liefert LOOCV unvoreingenommene Schätzungen (geringe Vorspannung). Aber Voreingenommenheit ist nicht das einzige Problem bei Schätzproblemen. Wir müssen auch die Varianz berücksichtigen.
LOOCV hat einehohe Varianzweil wir die Ausgabe von n Modellen mitteln, die zu einem fast identischen Satz von Beobachtungen passen, und ihre Ausgaben stark positiv miteinander korrelieren.
Und Sie können deutlich sehen, dass dies rechenintensiv ist, da das Modell „n“ Mal benötigt, um jede Beobachtung mit den Daten zu vergleichen. Unsere nächste Methode wird sich mit diesem Problem befassen und uns ein gutes Gleichgewicht zwischen Verzerrung und Varianz verschaffen.
Schnelle Implementierung der Leave-One-Out-Kreuzvalidierung in Python
aus sklearn.model_selection importiert LeaveOneOut
X = [10,20,30,40,50,60,70,80,90,100]l = LeaveOneOut() zum Trainieren, Testen in l.split(x): print("%s %s"% (Bahn, prüfen))
Produktion
[1 2 3 4 5 6 7 8 9] [0][0 2 3 4 5 6 7 8 9] [1][0 1 3 4 5 6 7 8 9] [2][0 1 2 4 5 6 7 8 9] [3][0 1 2 3 5 6 7 8 9] [4][0 1 2 3 4 6 7 8 9] [5][0 1 2 3 4 5 7 8 9] [6][0 1 2 3 4 5 6 8 9] [7][0 1 2 3 4 5 6 7 9] [8][0 1 2 3 4 5 6 7 8] [9]
Diese Ausgabe zeigt deutlich, wie LOOCV eine Beobachtung auf der Seite behält, während die Testdaten und alle anderen Beobachtungen in die Zugdaten gehen.
3. K-fache Kreuzvalidierung
Bei dieser Resampling-Technik werden alle Daten in k Sätze von nahezu gleicher Größe aufgeteilt. Der erste Satz wird als Testsatz ausgewählt und das Modell wird mit den verbleibenden k-1 Sätzen trainiert. Die Testfehlerrate wird berechnet, nachdem das Modell an die Testdaten angepasst wurde.
In der zweiten Iteration wird der zweite Satz als Testsatz gewählt und die verbleibenden k-1 Sätze werden verwendet, um die Daten zu trainieren, und der Fehler wird berechnet. Dieser Prozess wird für alle k Sätze fortgesetzt.
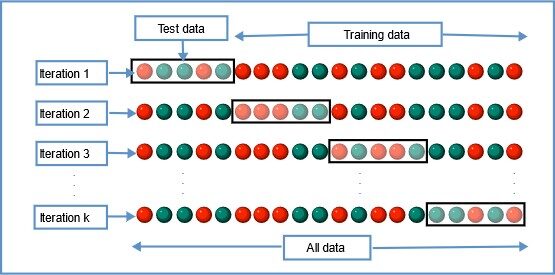
Bildquelle: Wikipedia
Der Durchschnitt der Fehler aller Iterationen wird als Schätzung des CV-Testfehlers berechnet.
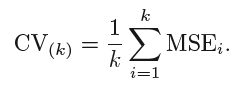
Ein k-facher CV, die Anzahl der k-fachen ist geringer als die Anzahl der Beobachtungen in den Daten (k < n) und wir mitteln die Ergebnisse k-angepasster Modelle, die aufgrund von Überlappung etwas weniger miteinander korrelieren zwischen Sätzen von k-Falten ist das Training in jedem Modell geringer. Dies führt zugeringe Varianzdann LOOCV.
Das Beste an dieser Methode ist, dass jeder Datenpunkt genau einmal in der Testmenge und k-1 mal in der Trainingsmenge enthalten ist. Mit zunehmender Faltungszahl k nimmt auch die Varianz ab (geringe Varianz). Diese Methode führt zudurchschnittliche Vorspannungdenn jeder Trainingssatz enthält (k-1)n/k weniger Beobachtungen als bei der Dropout-Methode, aber mehr als bei der Dropout-Methode.
Wie üblich wird die K-fache Kreuzvalidierung mit k = 5 oder k = 10 durchgeführt, da empirisch gezeigt wurde, dass diese Werte Testfehlerschätzungen erzeugen, die weder eine hohe Verzerrung noch eine hohe Varianz aufweisen.
Der Hauptnachteil dieser Methode besteht darin, dass das Modell ab null k Mal ausgeführt werden muss und dass es rechnerisch teurer als die Hold-Methode, aber besser als die Hold-Methode ist.
Einfache Implementierung der K-Fold-Kreuzvalidierung in Python
importar de sklearn.model_selection KFold
X = ["a",'B','C','D','e','F']kf = KFold(n_splits=3, shuffle=False, random_state=None) zum Verschieben, in kf.split test(x): print("Zugdaten",Zug,"Testdaten",Test)
Produktion
Bereich: [2 3 4 5] prüfen: [0 1] Bereich: [0 1 4 5] prüfen: [2 3] Bereich: [0 1 2 3] prüfen: [4 5]
4. K-fach geschichtete Kreuzvalidierung
Dies ist eine kleine Variation der K-Fold-Kreuzvalidierung. Was verwenden Sie?‘geschichtete Stichprobe’statt „Sampling“.
Lassen Sie uns schnell verstehen, was geschichtete Stichproben sind und wie sie sich von zufälligen Stichproben unterscheiden.
Angenommen, Ihre Daten enthalten Erfahrungsberichte zu einem kosmetischen Produkt, das von Männern und Frauen verwendet wird. Wenn wir die Daten nach dem Zufallsprinzip in Testsätze und Merkmale aufteilen, besteht die Möglichkeit, dass die meisten männlichen Daten nicht in den Trainingsdaten enthalten sind, aber in den Testdaten landen könnten. Wenn wir das Modell mit Beispiel-Trainingsdaten trainieren, die keine korrekte Darstellung der realen Population sind, wird das Modell die Testdaten nicht mit guter Genauigkeit vorhersagen.
Machine Learning Classification in Python – Part 1 | rocket loop
Hier kommt die geschichtete Probenahme zur Rettung. Hier werden die Daten partitioniert, um alle Klassen der Bevölkerung darzustellen.
Betrachten Sie das obige Beispiel, das eine Kosmetikproduktbewertung von 1.000 Kunden enthält, von denen 60 % Frauen und 40 % Männer sind. Ich möchte die Daten proportional in Test- und Trainingsdaten aufteilen (80:20). 80 % der 1000 Kunden werden so ausgewählt, dass 480 Bewertungen der weiblichen und 320 repräsentativen der männlichen Bevölkerung zugeordnet werden. Ebenso werden 20 % von 1.000 Kunden für die Testdaten ausgewählt (bei gleicher Vertretung von Männern und Frauen).
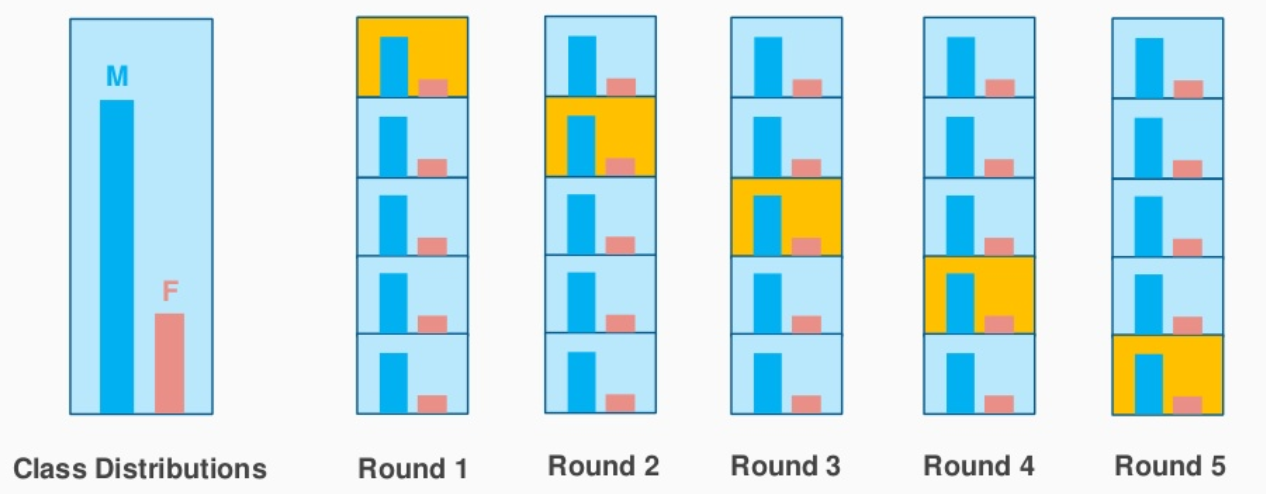
Bildquelle: stackexchange.com
K-Fold Stratified CV macht genau das und erstellt K-Folds, während der Stichprobenprozentsatz für jede Klasse beibehalten wird. Dies löst das Zufallsstichprobenproblem, das mit Halte- und k-fachen Verfahren verbunden ist.
Schnelle Implementierung der K-Fold stratifizierten Kreuzvalidierung in Python
aus sklearn.model_selection import StratifiedKFold
X = np.matriz([[1,2],[3,4],[5,6],[7,8],[9,10],[11,12]])y = np.matriz( [0,0,1,0,1,1])skf = StratifiedKFold(n_splits=3,random_state=Ninguno,shuffle=False)for train_index,test_index in skf.split(x,Yes): print("Train:" ,train_index,'Check:',test_index) X_train,X_test = X[train_index], x[test_index] y_train,y_test = y[train_index], Sim[test_index]
Produktion
Bereich: [1 3 4 5] prüfen: [0 2] Bereich: [0 2 3 5] prüfen: [1 4] Bereich: [0 1 2 4] prüfen: [3 5]
Das Ergebnis zeigt deutlich die nach den Klassen ‘0’ und 1′ in y’ geschichtete Klassifizierung.
Bias – Abweichungskompensation
Unter Berücksichtigung der Testfehlerratenschätzungen liefert die K-Fold-Kreuzvalidierung genauere Schätzungen als das Weglassen einer Kreuzvalidierung. Während die Hold-CV-Methode häufig zu Überschätzungen der Testfehlerrate führt, da bei diesem Ansatz nur ein Teil der Daten zum Trainieren des maschinellen Lernmodells verwendet wird.
In Bezug auf die Verzerrung liefert die Leave One Out-Methode unverzerrte Schätzungen, da jeder Trainingssatz n-1 Beobachtungen enthält (was so ziemlich alle Daten sind). Der K-Fold CV führt im Vergleich zum LOOCV eine durchschnittliche Verzerrung ein, die auf der Anzahl der k-Folds basiert, aber im Vergleich zur Haltemethode viel kleiner ist.
Letztendlich hängt die von uns gewählte Kreuzvalidierungstechnik sehr stark vom Anwendungsfall und dem Gleichgewicht zwischen Verzerrung und Varianz ab.
Wenn Sie diesen Artikel bisher gelesen haben, ist hier ein schneller Bonus für Sie.👏
sklearn.model_selectionhat Methodecross_val_scorewas den Kreuzvalidierungsprozess vereinfacht. Anstatt alle Daten mit der ‘Split’-Funktion zu durchlaufen, können wir verwendencross_val_scoreund überprüfen Sie die Genauigkeitsbewertung der gewählten Kreuzvalidierungsmethode
Sie können auf meinem Github nachsehenPython-Implementierungverschiedene Kreuzvalidierungsmethoden inKaggle Brustkrebs Fakten auf der Intensivstation.
Nachfolgend finden Sie einige meiner Artikel zum maschinellen Lernen.
Künstliche Intelligenz vs. Machine Learning vs. Deep Learning: Was genau ist der Unterschied zwischen diesen Schlagworten?
Eine vollständige Anleitung zur Datenanalyse mit Pandas
Wenn Sie Ihre Gedanken teilen möchten, können Sie sich mit mir unter in Verbindung setzenLinkedIn.
Viel Spaß beim Lernen!
Die in diesem Artikel vorgestellten Medien sind nicht Eigentum von DataPeaker und werden nach Ermessen des Autors verwendet.

