NOmachine learningdeals with the use and development of computer systems that can learn and adapt without following explicit instructions. To do this, they use statistical algorithms and models to analyze patterns in the data and draw independent conclusions for further analysis. The results of this model training can later be used to make predictions (with unknown data).
A model is a distilled representation of what a machine learning system has learned. Such a function is comparable to mathematical functions:
- It accepts a request in the form of input data,
- make a prediction about this
- and based on this provides an answer to a specific question.
Programming and training (with known datasets) the algorithm is an important first step. Secondly, it should be checked whether it can also be used for unknown data sets – and thus in practice. Only then do we know whether the model really works and whether we can trust its predictions. Otherwise it could be that the algorithm only remembers the data that it is fed with (overfitting/overfitting) and then cannot make reliable predictions for data sets unknown to it.
In this article, we show two of the most common problems in model validation: overfitting and underfitting. And how to avoid them.
(Video) Machine Learning Course – 12. Overfitting and Underfitting
Index:
- What is model validation (and what is it for)?
- What does overfitting (and underfitting) mean?
- How can overfitting and underfitting be reduced?
- Which model validation methods are there?
- Train Test Split
- k-fold cross-validation (CV k-fold)
- Single Exit Cross Validation (LOOCV)
- Nested Cross Validation
1. What is model validation (and what is it for)?
Definition: The model validation procedure describes the process of checking a statistical or data-analytical model for its performance.
It is an essential part of the model development process and helps you find the model that best represents your data. It also serves to estimate how well this will work in the future. Performing this assessment on the datasets used for training is not convenient as it can easily lead to the creation of over-optimistic and over-fitted models.
2. What does overfitting (and underfitting) mean?
Overfitting refers to a model that models the training data too well. Assuming it’s very specific to your training set.
Overfitting occurs when a model learns details and noise (random variations) in the training data to the point where it negatively affects its performance on new/unknown data. This is evidenced by the inclusion and learning of noise as a concept. The problem is that these concepts do not apply to new data and therefore negatively affect the generalizability (applicability to any unknown data set) of the model.
Low error rates and high variance are strong indicators of overfitting. she most likely isnon-parametric and non-linear models, which have more flexibility in learning an objective function. Therefore, many nonparametric machine learning algorithms include parameters or techniques to constrain the amount of detail the model must learn.
Decision trees are e.g. B. A non-parametric machine learning algorithm that is very flexible. This often leads to overfitting of the training data. However, this problem can be solved by pruning a tree after learning to remove some of the details it picked up during the learning process.
Overfitting is also common when the training data set is relatively small and the model is relatively complex at the same time. A very complex model can quickly map the training data very accurately – a very simple model, on the other hand, can quickly map the training data very imprecisely (this is referred to as underfitting/underfitting).
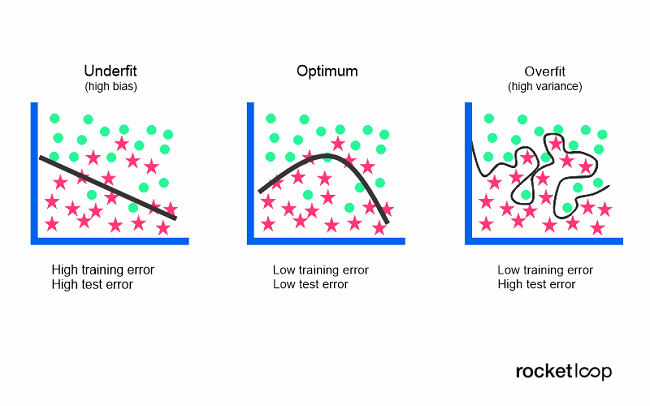
A very simple data model often cannot accurately capture the relationship between input and output variables. This results in a high error rate – both with training data and with unknown data sets. A high bias/error rate combined with a low variance are strong indicators of underfitting.
Since this behavior can already be observed during training, underfitted models are usually easier to recognize than overfitted models. The solution to underfitting could be more training time, more input functions, or less regularization – but more on that in the next section.
Both overfitting and underfitting lead to a very low overall validity of a model. However, if a model cannot be reliably applied to unknown data, then it cannot be used for classification or prediction tasks. The general application of a model to new data ultimately allows us to use machine learning algorithms to make predictions and classify data.
(Video) Kaggle’s 30 Days Of ML (Day-10): Underfitting, Overfitting & Random Forests
So the challenge is to keep the model as simple as possible on the one hand, but not too simple on the other. A perfect model – that is, one that is neither overfit nor underfit – is almost impossible to create. However, there are some methods and tools that can be used to rule out these negative effects with a high degree of probability. You will find out what these are in the next chapter.
3. How can overfitting and underfitting be reduced?
There are several methods to avoid overfitting and underfitting early on when training a model. We have listed the most important ones for you below.
Avoid overfitting in machine learning:
a) Shorter training time (early termination):With this method, you stop training before the model has stored much detail (including noise) from the dataset. However, with this approach there is a risk that the training process will be terminated too early – which in turn leads to the opposite problem of underfitting. Finding the “sweet spot” between underfitting and overfitting is the ultimate goal.
b) Train with more data:Expanding the training set with more data can increase the accuracy of the model and give it more opportunity to filter out the relevant relationship between input and output variables. However, this is only an effective method if you only provide clean and meaningful data. Otherwise, you’re just adding unnecessary complexity to the model, ultimately leading to overfitting.
c) data extension:While it is theoretically best to simply apply clean, meaningful training data, sometimes noisy data is intentionally added to make a model more stable. However, this method should be used sparingly (and usually only by experienced users).
d) Choice of resources:In this way, you identify the most important features of the training data in order to eliminate irrelevant – and therefore superfluous – features. This is often confused with downscaling, but it’s a different approach. However, both methods help you simplify a model to identify the dominant trend in the data.
e) Normalization:This is related to the previous resource selection element as it is used to determine which resources to eliminate. To do this, you apply a “penalty” to input parameters with larger coefficients, which then limits the variation in the model. There are several normalization methods (e.g. L1 and regularization or loop breaking) – but they all have the same goal: to identify and reduce noise in the data.
f) Ensemble-Methoden:These consist of a series of classifiers (like decision trees). You combine your predictions to find the most favorable outcome. The most popular pooling methods are bagging and boosting.
Avoid overfitting in machine learning:
a) Longer training time:Just as shortening the training phase reduces overfitting, lengthening reduces underfitting. As already mentioned, the challenge lies in the selection of the optimal model training duration.
b) Feature selection:If there are not enough predictive features, add more or those of greater importance. on onerede neuralFor example, you could add more hidden neurons. And in a forest more trees. This increases the complexity of the model, leading to better training results – but only to the point where overfitting begins.
(Video) Tensor-flow Overfitting and Underfitting Explained For Machine Learning
c) Smooth normalization:Applying the methods used to normalize the training data too rigorously can result in the features becoming too uniform. As a result, the model is no longer able to identify the dominant trend, resulting in an underfit. By reducing regulation, you can bring back more complexity and variation.
As you can see, finding the middle ground between underfitting and overfitting is like walking a fine line. To ensure that your model does not have any of these issues, you need to validate it. There are several methods to evaluate models in data science: The most well-known of these is certainly k-fold cross-validation. We would like to introduce these – and a few more – to you below.
4. What are the model validation methods?
model evaluation methods are used
- diesetting accuracyt between model and datajudge,
- Compare different models(in connection with model selection),
- eto predict how accurate the predictions are(associated with a specific model and dataset) is expectedwill be.
The validation thus serves to show that the model is a realistic representation of the system under study: that it reproduces the behavior of the system with sufficient accuracy to meet the objectives of the analysis. While the model verification techniques are general, you should make the process itself much more specific. Both for the model in question and for the system in which it will be used.
Just as the development of the model is influenced by the goals of the study, so is the validation of the model. At this point we only present some of the methods used – but there are many more. Which one you ultimately choose should be based on the specific parameters and characteristics of the model you are developing.
The basis of all validation techniques is the splitting of the data set when training the model. This is done to understand what is happening when you are presented with data you have never seen before. Therefore, one of the simplest methods is test train division.
1. Train Test Split
The principle is simple: you randomly split your data into roughly 70% for training and 30% for testing the model. However, overfitting can easily occur when optimizing with this method. Why? Because the model is looking for the hyperparameters that match the specific pull test you performed.
To fix this problem, you can create an additional validation set. This is typically 10-20% of the data that you reserve for later validation and therefore not used for training or testing. After you have optimized your model with split test training, you can use the validation set to validate that there is no overfitting.
But what if a subset of our data only contains people of a certain age or income, for example? This (worst) case is called sample bias. This is a systematic error due to non-random sampling of a data set (such as the population just treated) that makes some data points (individuals) less likely to be included than others.
Machine Learning Classification in Python – Part 1 | rocket loop
2. k-fold cross-validation (k-fold CV)
To minimize sample bias, let’s look at the validation approach a little differently. What if instead of a single division operation, we perform multiple divisions and validate all combinations of them?
(Video) Avoid Overfitting Using Regularization in TensorFlow | Python | TensorFlow
At this point comes thek-fold cross-validationin the game. She
- divides the data into k-folds,
- then train the data on k-1 folds
- and tests on the single fold that was omitted.
This is done for all combinations and the result calculated for each instance.
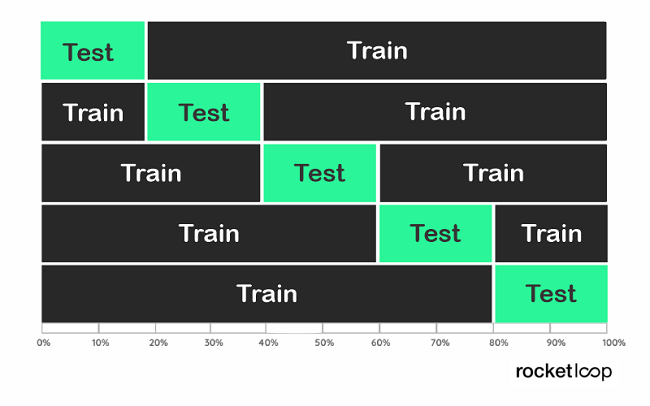
This will use all data for training and validation. But each data point (each fold) only once. A value between 5 and 10 is usually chosen for k, as this achieves a good balance between computational effort and accuracy. The advantage of this method is that you get a relatively variant-free performance estimate. The reason for this is that important structures in the training data cannot be discarded.
3. Single Exit Cross Validation (LOOCV)
Leave-one-out cross-validation is a special case of cross-validation where the number of folds equals the number of instances (observations) in the dataset. The learning algorithm is then applied once to each instance, using all other instances as the training set and the selected instance as the single-item test set. This method is closely related to the statistical methodJack Knife estimate.
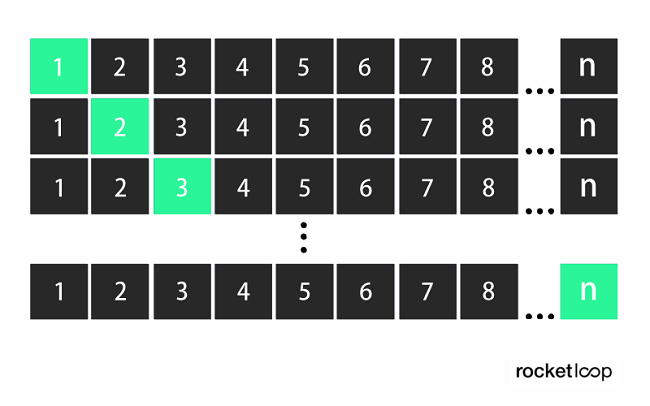
An instance is an instance in the training data and is described by several attributes. An attribute, in turn, is an aspect/trait of an instance (e.g. age, temperature, humidity).
However, the method is computationally expensive since the model has to be trained n times. Therefore, use it only when the underlying data set is small or you have the processing power for a correspondingly large number of calculations.
4. Nested Cross Validation
Model selection without nested cross-validation uses the same data to fit model parameters and assess model performance, which can lead to an optimistically biased assessment of the model (overfitting). Due to information leaks, we get a bad estimate of errors in the training or testing data.
To solve this problem, nested cross-validation comes into play, which allows you to separate the hyperparameter optimization step from the error estimation step. To illustrate, let’s nest two k-fold cross-validation loops.
- Dieinner loopfor theHyperparameter Adjustment
- like thisthe outsidefor theAccurate estimate
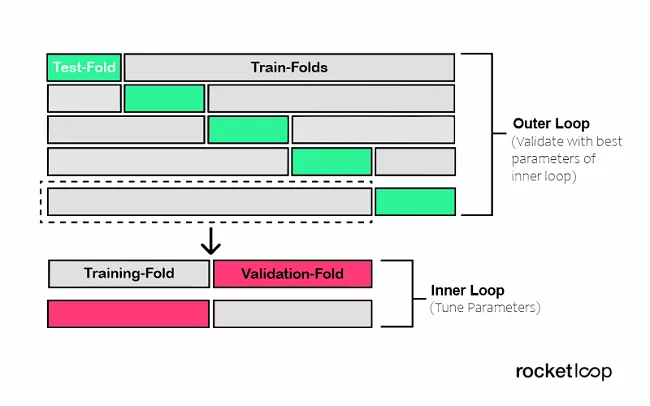
You are free to choose inner and outer loop cross-validation approaches. So you can e.g. B. Use the leave-one-out method for the inner and outer loops if you want to split by specific groups.
That was our brief overview of the main methods for validating a machine learning model. This brings us to the end of our article on the subject of “problem areas in model validation (and their solutions): overfitting and underfitting!”. arrived. We hope that the information and practical examples presented here will be helpful for your own software development project.
(Video) Neural Networks: Avoiding Overfitting & Optimizations [2020-08-11]
If you need assistance, we welcome you to us.Contactrecord for yoursoftware developmentCount on our experienced team – we look forward to your message. This saves you valuable introductory time that you can invest in building your own team so you can do the next product development entirely in-house!

